1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
| '''
***使用说明***
终端界面输入xbus2wp.py bus.xml xrspook。其中:
xbus2wp.py为脚本名字,bus.xml为BlogBus导出文件,xrspook为博主名字,3个参数以空格分开
若运行无误,输出的文件名为[原文件名_xbus2wp.xml]
脚本基于python3,适配WordPress 5.4.2(2020-06-18)
'''
import re, sys, getopt, datetime
from xml.dom import minidom
from time import time
def convert(inputFileName, owner, order='asc'):
""""""
try:
xmldoc = minidom.parse(inputFileName)
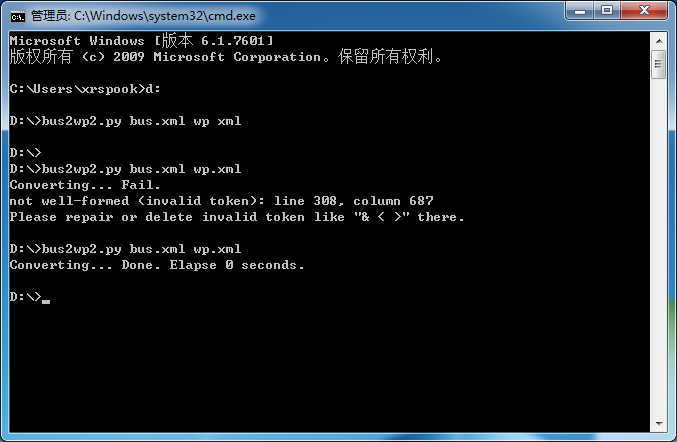
except Exception as e:
print ('Fail.')
print (e)
print ('Please repair or delete invalid token like "& < >" there.')
sys.exit(1)
bus = xmldoc.documentElement
logs = bus.getElementsByTagName('Log')
dom = minidom.Document()
rss = dom.createElement('rss') # rss是root,根元素
dom.appendChild(rss)
rss.setAttribute('version', '2.0')
rss.setAttribute('xmlns:content', 'http://purl.org/rss/1.0/modules/content/')
rss.setAttribute('xmlns:wfw', 'http://wellformedweb.org/CommentAPI/')
rss.setAttribute('xmlns:dc', 'http://purl.org/dc/elements/1.1/')
rss.setAttribute('xmlns:wp', 'http://wordpress.org/export/1.0/')
channel = dom.createElement('channel')
rss.appendChild(channel)
wxr_version = dom.createElement('wp:wxr_version') # 加入wxr戳,无戳无法进行WordPress导入
channel.appendChild(wxr_version)
wxr_version_node = dom.createTextNode('1.1')
wxr_version.appendChild(wxr_version_node)
busname = bus.getElementsByTagName('BlogName')[0] # 提取原BlogBus名字
busname_text = getElementData(busname).replace(' ', '_')
# create a list to contain items instead of appending them to
# channel directly in order to sort them of lately according to order.
if order == 'desc':
item_list = []
else:
item_list = None
for log in logs:
title = log.getElementsByTagName('Title')[0]
title_text = getElementData(title)
content = log.getElementsByTagName('Content')[0]
content_text = getElementData(content)
logdate = log.getElementsByTagName('LogDate')[0]
pubdate = getElementData(logdate)
writer = log.getElementsByTagName('Writer')[0]
creator = owner # BlogBus的writer根本没包含元素!
category = getElementData(log.getElementsByTagName('Sort')[0])
tagi = log.getElementsByTagName('Tags')[0]
tags = getElementData(tagi).split(' ')
new_tags = unique_tag(category, tags) # 新的wp标签里包含了原BlogBus里的分类与标签
comments = log.getElementsByTagName('Comment')
#-----
item = dom.createElement('item')
# handle title
title_element = createElement(dom, 'title', title_text, 'cdata')
item.appendChild(title_element)
# handle type
type_element = createElement(dom, 'wp:post_type', 'post', 'cdata')
item.appendChild(type_element)
# handle pubdate
pubdate_element = createElement(dom, 'pubDate', convertPubDate(pubdate))
item.appendChild(pubdate_element)
# handle creator
creator_element = createElement(dom, 'dc:creator', creator, 'cdata')
item.appendChild(creator_element)
# handle categories with domain
category_element = createElement(dom, 'category', busname_text, 'cdata') # 把BlogBus标题设置为分类,因为我要合并多个旧blog
category_element.setAttribute('domain','category')
category_element.setAttribute('nicename', busname_text)
item.appendChild(category_element)
# handle tags
for tag in new_tags:
tag = tag.replace('ñ', 'n')
tag = tag.replace('summary_of_BLF', 'summary_of_BLF(from_rincondebetty)')
tag = tag.replace('summary_of_EcoModa', 'summary_of_EcoModa(from_rincondebetty)')
category_element = createElement(dom, 'category', tag, 'cdata')
category_element.setAttribute('domain','post_tag')
category_element.setAttribute('nicename', tag)
item.appendChild(category_element)
# handle content
content_element = createElement(dom, "content:encoded", content_text, 'cdata')
item.appendChild(content_element)
# handle post_date
post_date_element = createElement(dom, "wp:post_date", pubdate)
item.appendChild(post_date_element)
# handle status
status_element = createElement(dom, "wp:status", 'publish')
item.appendChild(status_element)
# handle comments
if comments:
commentElements = createComments(dom, comments)
for commentElement in commentElements:
item.appendChild(commentElement)
if item_list != None:
item_list.append(item)
else:
channel.appendChild(item)
if item_list:
item_list.reverse()
for m in item_list:
channel.appendChild(m)
global filename # 输出设置
output = filename + '_xbus2wp.xml'
f = open(output ,'wb+')
import codecs
writer = codecs.lookup('utf-8')[3](f)
dom.writexml(writer, '', ' ' * 4, '\n', encoding='utf-8')
writer.close()
def unique_tag(category,tags): # 只保留唯一的标签
category = category.replace(' ', '_')
l = category.split() + tags
new_l = []
for item in l:
if item not in new_l and item != '(from_rincondebetty)':
new_l.append(item.replace(' ', '_')) # 替换空格为下划线
return new_l
def getElementData(element): # 获取节点数据
""""""
data = ''
for node in element.childNodes:
if node.nodeType in (node.TEXT_NODE, node.CDATA_SECTION_NODE):
data += node.data
return data
def createComments(dom, comments):
""""""
l = []
count = 0
for comment in comments:
count += 1 # 每篇文章的评论序号,没有序号,评论只能导入每篇最后一条
email = comment.getElementsByTagName('Email')[0]
homepage = comment.getElementsByTagName('HomePage')[0]
name = comment.getElementsByTagName('NiceName')[0]
content = comment.getElementsByTagName('CommentText')[0]
date = comment.getElementsByTagName('CreateTime')[0]
comment_element = createCommentElement(count, dom, email, homepage, name, content, date)
l.append(comment_element)
return l
def createCommentElement(count, dom, email, homepage, name, content, date):
""""""
comment_author = getElementData(name)
comment_author_email = getElementData(email)
comment_author_url = getElementData(homepage)
comment_date = getElementData(date)
comment_content = getElementData(content)
comment_id_element = createElement(dom, 'wp:comment_id', str(count))
comment_author_element = createElement(dom, 'wp:comment_author', comment_author)
comment_author_email_element = createElement(dom, 'wp:comment_author_email', comment_author_email)
comment_author_url_element = createElement(dom, 'wp:comment_author_url', comment_author_url)
comment_date_element = createElement(dom, 'wp:comment_date', comment_date)
comment_date_gmt_element = createElement(dom, 'wp:comment_date_gmt', comment_date)
comment_content_element = createElement(dom, 'wp:comment_content', comment_content, 'cdata')
comment_approved_element = createElement(dom, 'wp:comment_approved', '1')
# make the comment element
comment_element = dom.createElement('wp:comment')
comment_element.appendChild(comment_id_element)
comment_element.appendChild(comment_author_element)
# validate email and url
validEmail = validateEmail(comment_author_email)
if (validEmail):
comment_element.appendChild(comment_author_email_element)
validUrl = validateUrl(comment_author_url)
if (validUrl):
comment_element.appendChild(comment_author_url_element)
comment_element.appendChild(comment_date_element)
comment_element.appendChild(comment_date_gmt_element)
comment_element.appendChild(comment_content_element)
comment_element.appendChild(comment_approved_element)
return comment_element
def createElement(dom, elementName, elementValue, type='text'): #建立节点标签和节点
""""""
global owner
tag = dom.createElement(elementName)
if elementValue.find(']]>') > -1:
type = 'text'
if type == 'text':
text = dom.createTextNode(elementValue)
elif type == 'cdata':
elementValue = elementValue.replace('&', '&')
elementValue = elementValue.replace('<', '<')
elementValue = elementValue.replace('>', '>')
elementValue = elementValue.replace(''', '\'')
elementValue = elementValue.replace('"', '"')
# 大量替换与我的旧blog有各种编码的西班牙语字符有关
elementValue = elementValue.replace('©', '') # 版权标志
elementValue = elementValue.replace(' ', '') # 空格
elementValue = elementValue.replace('“', '“') # 左双引号
elementValue = elementValue.replace('”', '”') # 右双引号
elementValue = elementValue.replace('‘', '‘') # 左单引号
elementValue = elementValue.replace('’', '’') # 右单引号
elementValue = elementValue.replace('´', '´') # 单引号
elementValue = elementValue.replace('…', '...') # 省略号
elementValue = elementValue.replace('—', '—') # 破折号
elementValue = elementValue.replace('·', '·') # 分隔号
elementValue = elementValue.replace('°', '°') # 单位度
elementValue = elementValue.replace('¡', '¡') # 西班牙语反叹号
elementValue = elementValue.replace('¿', '¿') # 西班牙语反问号
elementValue = elementValue.replace('ñ', 'ñ') # 西班牙语n
elementValue = elementValue.replace('Ñ', 'Ñ') # 西班牙语N
elementValue = elementValue.replace('á', 'á') # 西班牙语a
elementValue = elementValue.replace('é', 'é') # 西班牙语e
elementValue = elementValue.replace('í', 'í') # 西班牙语i
elementValue = elementValue.replace('ó', 'ó') # 西班牙语o
elementValue = elementValue.replace('ú', 'ú') # 西班牙语u
elementValue = elementValue.replace('Á', 'Á') # 西班牙语A
elementValue = elementValue.replace('É', 'É') # 西班牙语E
elementValue = elementValue.replace('Í', 'Í') # 西班牙语I
elementValue = elementValue.replace('Ó', 'Ó') # 西班牙语O
elementValue = elementValue.replace('Ú', 'Ú') # 西班牙语U
elementValue = elementValue.replace('Ã', 'Ã') # 西班牙语A~
elementValue = elementValue.replace('ª', 'ª') # 西班牙语上标a
elementValue = elementValue.replace('º', 'º') # 西班牙语上标o
elementValue = elementValue.replace('<!--msnavigation-->', '')
elementValue = elementValue.replace('博主', owner)
elementValue = elementValue.replace('<i>', '')
elementValue = elementValue.replace('</i>', '')
elementValue = elementValue.replace('<br /><br />', '<br />')
elementValue = re.sub(r"(?:<\?xml.*?>)", "", elementValue)
elementValue = re.sub(r"(?:<[TDSFHI].*?>)", "", elementValue)
elementValue = re.sub(r"(?:<\/[TDSFHI].*?>)", "", elementValue)
elementValue = re.sub(r"(?:<P.*?>)", "<p>", elementValue)
elementValue = re.sub(r"(?:<(table|tbody|tr|td|div|span|img|script|font|hr|object|param).*?>)", "", elementValue)
elementValue = re.sub(r"(?:<\/(table|tbody|tr|td|div|span|img|script|font|object).*?>)", "", elementValue)
elementValue = re.sub(r"\n", "", elementValue) # 把替换造成的空行删除
text = dom.createCDATASection(elementValue)
tag.appendChild(text)
return tag
def convertPubDate(date, timediff='+0000'):
"""
convert 2003-08-22 16:01:56
to Thu, 23 Aug 2007 05:47:54 +0000
"""
year, mon, day = int(date[:4]), int(date[5:7]), int(date[8:10])
time = date[11:]
aday = datetime.datetime(year, mon, day)
d = {'1':'Mon', '2':'Tus', '3':'Wen', '4':'Thur', '5':'Fri', '6':'Sat', '7':'Sun'}
m = {'1':'Jan', '2':'Feb', '3':'Mar', '4':'Apr', '5':'May', '6':'Jun',
'7':'Jul', '8':'Aug', '9':'Sep', '10':'Oct', '11':'Nov', '12':'Dec'}
weekday = d[str(aday.isoweekday())]
month = m[str(mon)]
pubdate = "%s, %d %s %s %s %s" % (weekday, day, month, year, time, timediff)
return pubdate
def validateEmail(email):
'''
'''
pattern = r'^[0-9a-z][_.0-9a-z-]{0,31}@([0-9a-z][0-9a-z-]{0,30}[0-9a-z]\.){1,4}[a-z]{2,4}$'
p = re.compile(pattern)
m = p.match(email)
if m:
return True
else:
return False
def validateUrl(url):
'''
'''
pattern = r'^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$'
p = re.compile(pattern)
m = p.match(url)
if m:
return True
else:
return False
def main(argv=None):
global filename
global owner
if argv is None:
argv = sys.argv
# parse command line options
args = sys.argv[1:]
order='asc'
if (len(args) == 2):
print ('Converting...'),
sys.stdout.flush()
start = time()
filename = args[0].replace('.xml', '')
owner = args[1] # BlogBus没把博主名字输出,只能手动
convert(args[0], args[1], order)
end = time()
print ('Done. Elapse %g seconds.' % (end - start))
if __name__ == "__main__":
sys.exit(main())
</p> |